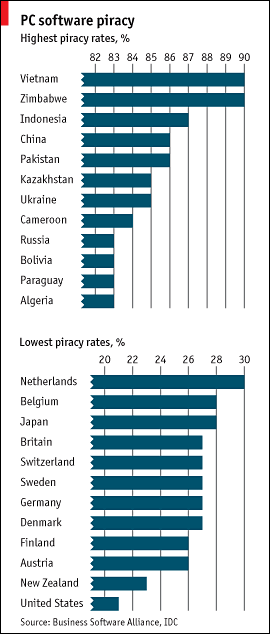
Going "regional" is ALWAYS a very good idea when searching. We have already seen how adding a simple .ru to
our queries can help. But why Russia? WHERE should we search? Which are the, how should I say? the "less copyright-obsessed" countries?
Here
you can
see a interesting
"piracy subdivision" published this summer by
The
Economist.
We may as well use these 'scarecrow' data (produced by
US-lobbyist Robert Holleyman's "Business Software alliance" in order to scrap some money)
for our own purposes...
And look! As you can see, Vietnam, Zimbabwe, Indonesia, China, Pakistan, Kazakistan, Ukraine, Cameroon,
Russia, Bolivia, Paraguay and Algeria seem to have a more relaxed attitude towards
patent holders. Good to know :-)
Here the relevant country codes:
.vn, .zw, .id, .cn,
.pk, .kz, .ua, .cm,
.ru, .bo, .py and .dz,
codes, that we could use to restrict searches only and/or
especially to such relaxed places.
Of course some of these countries are just tiny local niches, with next to no activity and
extremely weak signals, and can be ignored: throwing our clever queries in -say- Zimbabwe or Cameroon
we'll probably just wasting our (or our bots) precious searching time..
Let's say that -in general-
.vn(Vietnam),
.id (Indonesia), .cn (China), .pk (Pakistan),
.ua (Ukraine) and .ru (Russia) look promising enough. We may add
-out of our experience-
Iran, Korea, Bulgaria and India (.ir, .kr, .bg and .in).
So let's go local: let's visit China,
where we can find, among hundreds other, for instance
this link,
that requires just some guessing capacity (or some understanding of Chinese :-)
Of course we should also have a look
in
Vietnam,
in Russia/Ukraine (where
we will at once retrieve our Target and
as many other programming books as you fancy),
and
here is how
you would search in KOREA or in
RUSSIA
using MSN Search.
Caveat: this was all just academically speaking, duh. Once again: seekers don't need to download anything from
the web, since they can always find their targets again and again if and when needed :-P
IRC channels and blogs
Searching through IRC channels
and blogs can be -for specific targets- quite useful. However the ratio noise/signal is
quite bad on these channels, and therefore IRC-searching and blog-searching is -in many cases- a
waste of time if compared to more effective searching
techniques.
After all, and behind the hype, blogs are just messageboards where only the Author can start a thread, and IRC channels need, in order to be useful, a lot of
social engineering.
I'll just direct you to some
blogs search engines and to some
IRC search engines like
this one. Nuff said.
Various "uncommon" search engines
At times simply switching to less known (but quite interesting) search engines can cut mustard.
Here's a related search with
kartoo
and here's another search using gigablast.
Finally, since we are speaking of a programming language, we may also have a look at the recent google codesearch:
return lang:python gives 283000
scripts, enough for some serious studying. Samo with MSNsearch macros.
So we found our targets again and again using a palette of different searching colours. These are all paths that lead into
the forest, and you'll be able to find many more on your own. Now let's go back to the theory.
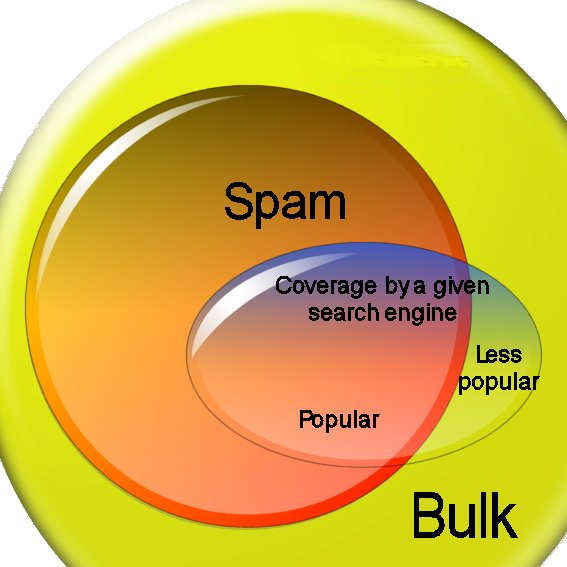
| Search engines' spamming (& "popularity") | top |
Google alone and you're never done
Google's results, after many years of legendary quality, are
now being spammed more and more.
Using a plethora of methods (cloaking, doorway pages, hidden text, blog-farms, you name it)
the SEO beasts ("search engines optimizators"
they have the cheek to call themselves) deny everybody the possibility to gather real knowledge
pushing up
their crap commercial sites into the first positions of the SERPs.
 |
|
Of course you can apply some countermeasures:
users -rather than spammers- should be able to influence the ranking of search results and some
search engines (MSNsearch's until a few months ago had beautiful
sliders
-now MSNlive has
macros though-
and Yahoo still has philtron)
provide users with the opportunity
to influence -at least rudimentary- the ranking algorithms.
A notorious case is the infamous 'popularity' ranking criterion. This you should by all means avoid or slide to insignificancy, since
it is eo ipso tantamount to crappiness.
Contrary to
what search engines' algos designer still seem to believe, TURNING POPULARITY DOWN if given half a
chance, is very important, since for humans with brains what -say- some idiots in Idaho are massively looking for
has no relevance whatsoever. "Sites popular for zombies" are exactly those sites that you will never need. Remember the beautiful
old trick of adding a site:edu or site:org specification to all your searchstrings per default:
all the "com" sites will disappear: good riddance.
|
For search engines that do not allow any algo fine-tuning, a possible defensive approach is the "yo-yo" approach:
jumping from the start
onto lower SERPs and then going slowly back up.
Such methods can soon prove
even more crucial for Internet searching purposes:
while google may not be yet a sinking boat, anyone can
see how much water is already leaking through its many spammed holes.
So we have to refine our seeking techniques.
Instead of just using google again and again, every time we
begin a search, we should
carefully consider how and where we start our searches, delve a little more
inside
our own specific requirements, and avoide wasting too much time
on irrelevant side paths... 
Quaeras ut possis, quando non quis ut velis
There are various strategies you can use when searching the web.
Some are more relevant for LONG TERM searching, some
on the contrary, for SHORT TERM searching.
But even the various simple techniques we used today (searching
for mp3s and books) can and should be used together with the main
search engines. On the ever moving web-quicksands
it does not make much sense to give a list of links to places where you can
"search alternatives". It is better, I believe, to (try to) show directly how to "search alternatively".
Of course there are various important non commercial databases, like Infomine (http://infomine.ucr.edu),
Librarians Internet Index (http://lii.org), The Internet Public Library (http://www.ipl.org/) Resource Discovery Network (http://rdn.ac.uk),
Academic Info (http://www.academicinfo.net/), The Front (for journals: http://www.arxiv.org/multi?group=math&%2Ffind=Search)
and finally the best one of all: The Open Directory Project (http://dmoz.org).
These are all
possible alternatives to a single approach limited to the main search engines.
Yet lists of links are and remain just that: lists of links. Bound to decay into
obsolescence.
We have seen some alternative approaches. Practice them on your own subjects and interests. Once you learn how to seek, the world is yours.
Cosmic power for free.
Nil perpetuum, pauca diuturna sunt
An easy assignment for this evening:
(just in order to practice the various techniques explained today, lest you forget everything):
find the new 1120 pages - September 2006 - second edition
of our target Core Python Programming by Wesley J. Chun, (Prentice Hall, ISBN: 0132269937)
This search should take you at most 10 minutes if done now (and just a few seconds in a couple of months,
when the book will have percolated the Web).
And now I'm finished.
Thank-you for your patience. Any questions?
SEARCHING THE PAST
(DISAPPEARED SITES)
http://webdev.archive.org/
~ The 'Wayback' machine at Alexa: explore the Net as it was!
Visit The 'Wayback' machine at Alexa,
or try your luck with the form below.
Alternatively, learn how to navigate through
[Google's cache]!
Alternatively a new "preservation"
project from Webcapture:
the International Internet Preservation Consortium is coming along.
| aap | All the various main search engines. | top |
A quick tour of the main search engines...
Uhhh.. almost forgot, a small book-searching present for those that solved the assignment (all others shouldn't look):
finding Ubuntu books
back to portal
back to top
(c) 1952-2032: [fravia+],
all rights reserved, all wrongs reversed
|


{kind=link}