Instructions &
Caveats (Why should anyone use a "not google" search engine at all?)
You would be well advised to try (at least some of) the various search engines listed on this page, which
has been defined as
both "a fine tool and a powerful weapon for searchers". Search engines use
in fact quite different algos, which gives indexes that do not overlap that much and thus offer
searchers the possibility
to fish results that they wouldn't even see if they would stuck onto just one index. In other words:
if you always limit yourself to google you 'll just cover (far) less than
one half of the "visible" web (and probably not even 1/5 ~ 1/10 of the hidden one). This is
true even if google offers -as it does- very good precision and failry broad recall (yet
check our own relevance comparisons and heed anyway the spamming problems google is subjected to).
How big is the web?
In July 2008 Google "was aware" of over a trillion pages
(http://googleblog.blogspot.com/2008/07/we-knew-web-was-big.html)
..."and the number of individual web pages out there is growing by several billion pages per day". However many of these
pages just represent auto-generated content and have NOT been indexed (see "links to unindexed" above).
Obviously, if you would really begin indexing and
counting auto-generated pages the
amount would quickly reach infinite: a large chunk of this "trillion"
will be auto-page-generating sites that return a page of junk whatever input URL you try (those same bastards that
pollute our searches). Many others will be just login and stats pages. These google's results are just a trillion 'discovered' URLs,
not a trillion URLs actually indexed, thanks god.
The letter "a",
for instance, often used for this kind of "quick checking", gives (april 2009) in google "just"
16 billion pages
(or 18 billions... search engines' results vary every few minutes, their "tides"
probably depend from the moon position :-) Anyway
the "trickyer" a OR a
query
gives us in google slightly more:
19,330,000,000 pages.
This seems to be consistent with google's own hints.
Now yahoo, that has a bigger index (in 2005 had already 20 billions), gives nowadays for "a"
43,100,000,000 pages, while the "cool" CUIL,
which claims "the biggest index of them all", signs over 121 billions pages!
This said -as all searchers know- the quality of the algos is king, while "index size" is -as such-
just accessorial. The real problem is always the relevance, coherence and reliability of the delivered results.
Again: precision
and recall are not the same thing.
Despite the previous advice to always use more search engines when searching, there are good resons
to get familiar with google's advanced parameters.
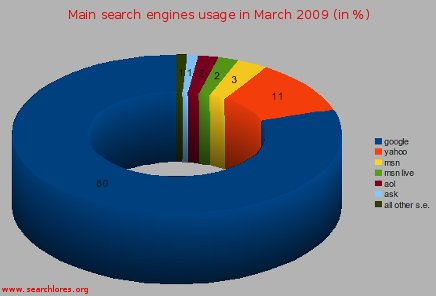
Since the usage of google, relatively to all other engines, has actually further increased (march 2009:
google 80% | yahoo 11% | msn 3% | aol 2% |
msn-live 2% | ask 1% | all other s.e. 1%, and since google is gaining
one percentage point per trimester (no matter what the other engines offer, and we doubt that CUIL will break this hold),
we have prepared an in depth, specific,
google page that seekers are encouraged to visit.
As said, this page is both a tool and a useful weapon, especially when preparing a long term search.
Just copy this page (or even better: the quick forms page onto your harddisk as
c:\main.htm (or whatever), and then bookmark it there and
use it (after having edited or thrown away anything you fancy)
in order to perform effective searches on the web
using any main search engine and starting from an unpolluted jumping off place, a page that has as few frills as
possible and as many useful forms as we know of. A page that you can modify -and ameliorate- yourself (feedback, in that case,
would be appreciated).
The main reason you should use more than one main search engine is that
search engines' results overlap FAR less than you would think. Ad hoc studies
point out that around 3/4 of the results of a given search are UNIQUE for each search engine.
Remember that search engines list only the first part of any BIG DOCUMENT:
the size varies.
Google had a famous limit of 101K, which was abolished in January 2005, the new limit should be around 150K. These
limits are very annoying when dealing with large documents (or on-line books).
Note also that just because one, hundred, or thousand pages from a given site are crawled and
made searchable trough one of the main search engines, this does not guarantee that
every page from an indexed site has really been crawled and indexed. This shortcoming
hits not only 'new' pages, that can take MONTHS to be indexed: beehives
of spiders harvesting
a site often MISS whole subdirectories, old and new. Useful material may
be all but invisible to those that only use 'main' search tools to seek.
Moreover anyone that uses regularly google (for instance, but other search engines are
not that different) will have noticed how polluting commercial sites results nowadays
are. Would
a search engine introduce a new, simple "please hide all commercial sites form your SERPs" (Search
Engines Result Pages) option, or switch, or slide, it would probably become king of the hill in a couple of months.
Therefore, seen the commercial-oriented pollution of the web, you
would be
well advised to use regional engines, usenet and other
specialized or targeted search tools and combing
techniques and also to rely on your own bots as well, when searching your various targets.
Note that you can also easily search and find targets
that do not
exist any more :-)
ALTAVISTA ADVANCED
SEARCH
[Only 400 results viewable]
Iis index is now provided by Yahoo that bought and promptly crippled altavista 'together with Fast/Alltheweb) in 2004.
AND,OR,(),NOT,NEAR,",*
link:text
(search for links to 'text')
anchor:text
(search for links with the description 'text')
url:text
(search for given text in the url)
domain:targetdomain
(search files within 'targetdomain')
host:hostname
(search files on 'hostname')
title:text
(search 'text' inside the title tags)
applet:text
(search Java applets named 'text')
image:filename
(search images with such 'filename')
Read the Altavista
in depth page! Spammed as if there were no tomorrow &
very badly commercialized. The idiots behind altavista's marketing managed to
ruin the best search engine of the middle nineties. It was for a long time THE ONLY
search engine which was TRULY BOOLEAN, hence offering truly amazing opportunities to real seekers...
(once having taken care of the spam).
Altavista algos'
main drawback is that they were very easy to spam, so you mostly got
useless results in the
first 20-30
positions: "hic alta, hic salta" (a seekers' proverb):
experienced searchers mostly
jumped directly in the middle of altavista's
results lists.
Altavista became the 'dead links
champion' among the 'main' search engines.
Kart00
A "Graphical" search engine, rather interesting result clusters. Here follows the text search form,
but by all means try its cartographic interface
Ujiko
Another "Graphical" search engine by the guys at kartoo, rather interesting
result clusters. Here follows a raw text search form,
but by all means try its cartographic interface instead!
Dicy
Another "clustering" search engine... associated phrases and related keywords galore!
Dicy is a powerful and unique search engine that searches the Internet with a graphical "flower"
format and retrieves on the fly users releated and possiblealternative relevant searches.
(Here, for interested seekers, the very structure of their spider, captured on my servers :-)
Mooter "The power of relevance"
Another "clustering" search engine, from Oz. "Starbust" technique. Original keywords are highlighted.
By all means, do click on "next clusters" once you get your first SERP.
Dmoz
The "open directory project". The best and
most authoritative directory on the web, can be quite useful, especially when starting a broad query
The alpha and omega of all relevant searches. Copied and scraped by all web-thieves and search
engines-spammers: real
gems lurk inside dmoz. Be careful and always try to avoid all dmoz's clown-clones à la http://www.answers.com/
Baidu
The powerful chinese Google alternative... with CACHE!
"...the world's second largest independent search engine..."
(a compound engine with some own and blog results)
IceRocket uses innovative metasearch technology to search the Internet's top search engines,
Yahoo, MSN, Ask, and many more.... Based in Dallas, so beware :-)
(hard to say if this is useful or not)
"Save, search and share your Personal Web. Furl it"
"Furl saves a personal copy of any page on the Web and lets you to find it again instantly, from any computer.
Share the sites you find, and discover useful new sites. Become a member to start building your Personal Web"
Fact is you can use some of the 'comments' this s.e. will dig.
The Entireweb
This is -for some queries- a very useful search engine, highlights query words in the result snippets
and clusters on request results from the same server. Check it!
The Wayback machine
This is not only a -powerful- search engine,
but also an incredible stalking tool! Explore the Net as it was!
More than 50 BILLION DOCUMENTS (April 2009)
Has NEAR operator! (November 2006)
20 BILLION DOCUMENTS (End-September 2005)
Visit the ad hoc YAHOO page
WARNING: Yahoo has been moved to its specific page, where you will find a
wealth of information. Here only a few masks and some info:
YAHOO
[Once Yahoo had only 677 results viewable, now the SERPs stop at 1000]
For info on Yahoo's (Inktomi's) rich syntax, see Nemo's essay (September 2005)
Yahoo is now one of the three "big players" (google, MSN and
Yahoo) and claimed at the beginning of September 2005, to
have indexed 19 billion sites (against google's 8 billion). A few weeks later Google claimed 25 billion docs (against Yahoo 20 billion).
Yahoo had indexed in March 2009 more than 50 billion documents.
In July 2008
google stated "being aware"
of "more than a trillion documents".
Since the indexable Web runs around trillions docs (and is still growing by some billion pages everyday)
this 'race' is rather pointless :-)
(More on google's ad hoc section)
EXCITE
[Only 4011 results viewable]
AND,OR,(),NOT,,", Excite is a classical
example of just another
'ignoble corporate merge'. Just click on the link above and look at it! See?
Idiotical & useless, obsolete (late-ninety)
'portal' approach. As a consequence
it ceased to be a major player since January 2002 (when "Infospace" killed it injecting tons of
paid -and hence bogus- search results). This applies to all mergers btw: attempts to escape
the fate of pyramide schemes always forebode catastrophes.
The Italians and Germans @ Tiscali
have tried to revamp this "engine on the sunset boulevard".
It is still full of
pay-per-click crapola, though, so
few searchers in their right minds use it.
Visit the ad hoc GOOGLE page
WARNING: Google has been moved to its specific page, where you will find a
wealth of information. Here only a few masks:
Google shoots for the lowest common denominator zombie
being able to find stuff, yet allows power users to take advantage of the hidden advanced features
Simple Google
Advanced GOOGLE (only 3% of users take advantage of it... pity the poor 97% zombies :-)
In November 2004, probably countering Microsoft's MSN arriving "live" search, google suddendly
*doubled* its indexed pages, claiming now a total of up
to 8 billion pages, which corresponded, approximately, to
1/4 of the 2004 web (which was around 35 billions pages according to our own data
for that year. In March 2009 we calculate **trillions** of pages and documents). One wonders
where they kept hidden all these suddendly appearing billions pages until november 2004. Clear sign
of the existence of more deep indexes for the powers that be, if you ask me :-)
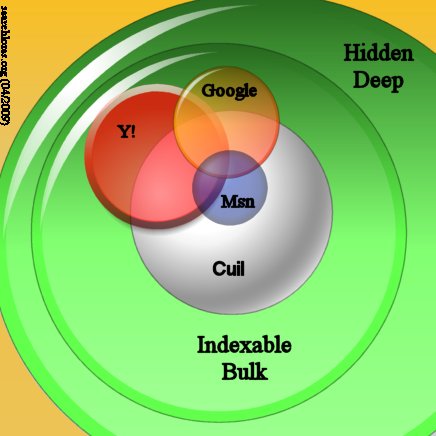
The biggest index seem to belong (April 2009) to cuil
(circa 120 billions), followed by
yahoo (circa 50 billions),
google (circa 20 billions), and MSN.
LYCOS
[Once upon a time one of the few search engines to really deliver
as many results viewable as you did actually get from its index!]
The Lycos search engine as such no longer rules. Their index is bad, their evident commercial bias
is masochistic (to say the least) and their remaining hopes prolly dwells inside their new beta lyGO "visual"
search engine (see below)
Booleans: AND OR NOT & quotes "" Also you
might
limit to a given site: &dfi=www.searchlores.org or set a
geographical constraint (doesn't seem to work though): ®ion=ch
Adult filter switch: &adf=on | some | off
HEAVILY comercially polluted compound engine, use at own risk
A "visual search" engine, still in beta, part of Lycos.
Useful for a quick evaluate with your eyes (and "zen-searcher feelings") session. A pity their index is Lycosian
The refine option is in-built: the SERPs (results pages) organize the information by vertical columns
of refining significance (if available). Sometime the results are kinda weird (rapidshare
gives one column "cindi sexonthebeach" for instance), but they offer two options: "more" and "related".
There's also an "integrated history feature" for unwashed
that don't know how to open a link inside a new tab. As "visual" serahc engines go, searchme.com seems still better, though
A "visual search" engine, still in "Early Beta/Late Alpha Preview Release", delivered by some indian programmers
Here the bla bla: "Launched in "early beta/late alpha" mode on February 2009 after stealth development in Bangalore, Delhi, and London, Yauba is based on over 25 years of cutting edge research from the Indian Institutes of Technology, the University of Delhi,
the Massachusetts Institute of Technology, Harvard University, and the University of California at Berkeley"
Can search
"All Places", "Internet Sites", "Real-Time Search", "Mainstream News", "Social News", "Blogs", "Answers", "Images", "Videos", "PDF file",
"Word files","Powerpoint files" and "Social Networks". Parameter is e.g. &target=blog
Results seem not bad at all. Granted, not always as deep and relevant as some other main search engines, but quite promising for a
relatively low financed attempt. Algos as yet unstudied, we will see.
Privacy claims: "ensures absolute privacy and doesn't collect any personally identifiable information
(visited websites, search history, IP address, physical location... etc.) on its users.
All records are automatically deleted from yaouba's servers" are not verifiable, but would be an
added bonus... if true.
Has an anonymous automatic proxy service:
click on results to directly visit any external site or click the green "Visit anonymously" link
to browse them anonymously through Yauba's own proxy servers.
Seems also useful as engine for a quick evaluate with your eyes (and
similar related "zen-searcher feelings") sessions.
As "visual" search engines go, not bad at all I would say.
A "visual search" engine, with BIG snapshots. Quite interesting.
Most useful for the quick evaluate with your eyes (and "zen-searcher feelings") session:
the results are far from perfect, but browsing the snapshots can be useful, especially when exploring the web in order to
quickly eliminate what you surely do not want. About their index, Randy Adams, boss of searchme.com, wrote that
"we have about 60 billion pages in our link index with about 2 billion active".
A very nice aspect of their very big snapshot collection is that you can bypass the site authors completely,
e.g. checking past content (if you check quicker than searchme's reindexing bots) and that
such approach still represents a full legit "fair use" of the web, with bona pace of the beastly SEOs and
other assorted paranoid patent & copyright lackeys (same spit-pot scrapping morons that whine and snivel
"against" cached pages, btw).
In fact the biggest appeal of this specific engine is exactly their "big snapshot" + "relevant text" offer.
Note that there is a "searchme lite" option, with less graphic frills, smaller snapshots and of course
more speed when searching. Yet the decent size of the full sized (not lite)
searchme engine, which allow you to actually READ the text, can allow a far better evaluation and seems
more useful for the educated seeker. There's an obvious trade off between
"speed" versus "evaluation depth", though. So try both "searchmes" and judge by yourself.
Gigablast This was a very thorough search engine until 2005, deemed quite good by most seekers (a rare
compliment). It was for instance the only search engine that did offer meta tags in the results list, it
also offered a
"ip numbers" search option and many more advanced parameters.
Unfortunately gigablast was idiotically "downgraded" and thus simplified into uselessness.
Decadence of the web? Just compare below
the old search mask and the old options (now not working anymore) and the new, working but "moronized" search mask.
Note that the advanced search page doesn't work but
still exist. Equally
ineffective are now the "age within" restriction
parameters visible at http://www.gigablast.com/.
Gigablast still
has a useful cache and it gives the publishing date of the resulting pages (and their dimension).
Its "giga bits" feature offers some clustering as refining option.
Factbites, quite interesting australian aggregator, more encyclopedia than search engine
ASK
"A good index & old teoma's good technology. Using its "DATE RESTRICTION" params you can squeeze some relevant results"
This was the old askjeeves search engine,
started in 1997, that went through many changes over the years. In the fall of 2001
"Ask Jeeves" purchased teoma's "à la combing" search
technology and incorporated it into askjeeves (teoma's forte was mainly "Subject-Specific Popularity" whereas e.g.
links to a searching site from other searching sites have more weight than links from -say- cactus owners).
As
usual with all stupid mergers, askjeeves first
crippled -and then in 2006 definitely killed- teoma.
The askjeeves name went also back to "ask".
Hence ask uses "Subject specific popularity" to organize the web into cluster topics.
Also it did retain some meta search engine aspects:
some answers coming from dogpile and about.
Ask claims the following:
"Our ExpertRank algorithm goes beyond mere link popularity (which ranks pages based on the sheer volume of links
pointing to a particular page) to determine popularity among pages considered to be experts on the topic of your search.
This is known as subject-specific popularity. Identifying topics (also known as "clusters"), the experts
on those topics, and the popularity of millions of pages amongst those experts - at the exact moment your
search query is conducted - requires many additional calculations that other search engines do not perform.
The result is world-class relevance that often offers a unique editorial flavor compared to other search
engines."