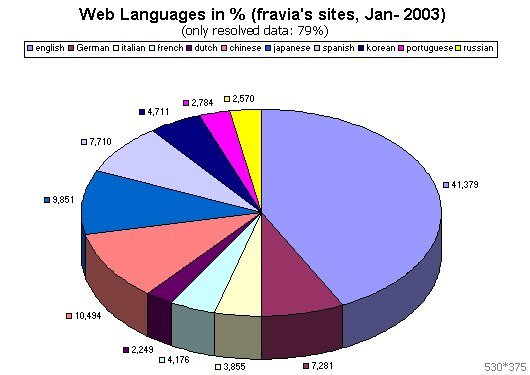
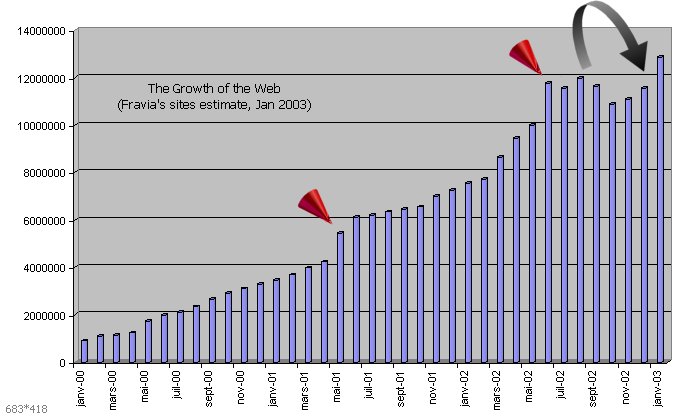
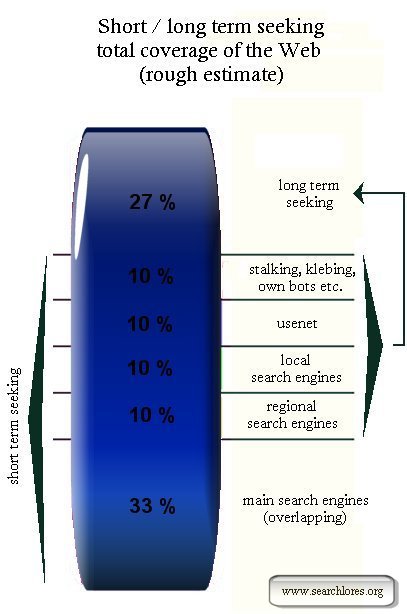
| | I have been invited to held a 2.30 hours workshop in a London university on 28 February 2003, these data and images could prove useful. |

Introduction Learning to transform questions into effective queries
Searching for disappeared sites Netcraft
rabbits.htm slides snippets Opera "opensourcing"
fast, google and teoma pro and contra Some reading material