A completely new wave of music searching has opened up through the relatively recent
mp3 blogs phenomenon, but usually it is MUCH simpler to just fetch the music you
need from the web any time you need it.
See the Combing webbit above.
Your phantasy is the limit!
Simply adding for
instance "4.6M" (or whatever similar you may fancy) to your querystring
will ensure that there are enough big and juicy MP3
in your targets: imagine lennon mp3 OR ma4 OR ogg intitle:"Index of" -metallica +"4.6M"
Most simple trick:
"index of" imagine m4a|wma
Another one (for music videos):
?intitle:index.of? "crazy frog" wmv "axel f"
or
?intitle:index.of? "madonna" wmv
Another one (for mp3 & co):
intitle:index.of + mp3 + "garfunkel" -html -htm -php -asp -txt -pls
Another one:
intitle:index.of + "mp3" + "band name" -htm -html -php -asp
Or even this, found with the previous query, so big that it may crash our browsers...
http://24.91.184.80/jserver/files/music/
or
http://mensa.familia.rebello.nom.br/media/Som/MPG_RA_VQF/Mp3/,
found through
imagine lennon mp3 OR ma4 OR ogg intitle:"Index of" -metallica
Some of the webbits we use for images work for music as well:
intitle:"index of/" "Apr-2004" "jpg" garfunkel
However, all these tecniques are overkill. In fact the amazing thing is that
even the most stupid searches, those that should NOT work, will give results:
madonna index.of mp3... q.e.d:
wherever, whenever, whatever.
Here are, as promised, some "privated investigation related magic"...
Finding photos BY CAMERA model
http://photos.alexa.com/
This is interesting because is part of the now public Alexa indexes: http://websearch.alexa.com/welcome.html
How to subdivide a query in manageable chunks (by Various Authors)
Do any search engines
or techniques exist to get more than -say- 1000 results from a search engine?
Usually you just refine your search.
You can narrow your query in various ways:
eliminating crap (the infamous -tits example)
adding broader -but relevant- terms ("digital photography": 20.400.000, +"shutter priority"= 190.000 +tiff"=40.500)
and with the results it is still good to jump first
to -say page five or ten, and then go backwards when evaluating the results :-)
If you have time, you can try things like these on Google
(the strategy for other search engines is mutatis mutandis
the same):With this kind of strategy
you can divide your SERPs in more or less four equal parts. If you use another common keyword or feature,
you can double the number of equal sets, for each new keyword...
There is a more direct way to achieve what you are asking,with the antipagination extension in firefox.
https://addons.mozilla.org/extensions/moreinfo.php?id=853
It flattens result pages (even works in forum pages)
There is a userjs that works in opera too and does the same only for google's result pages here:
http://userscripts.org/scripts/show/1392
Another trick:
blabla -inurl:htm 1.680.000
blabla -inurl:html 2.050.000
the differences are noticeable after the first pumped results
of course you can add and play with -/+ php or -/+ pdf or regional parameters (-/+fr -/+nl etcetera)
1) Sourceror2 (by Mordred & rai.jack)
try it right away
Right click and, in opera, select "add link to bookmarks"
javascript: z0x=document.createElement('form'); f0z=document.documentElement; z0x.innerHTML = '<textarea rows=10 cols=80>' + f0z.innerHTML + '</textarea><br>'; f0z.insertBefore(z0x, f0z.firstChild); void(0);
javascript:document.write(document.documentElement.outerHTML.replace(new RegExp("<","g"), "<"));
2) Another google approach
http://www.google.com/complete/search?hl=en&js=tru%20e&qu=photography
3) Another google approach (by Mordred)
Here is a
way to gather relevant info about your target
"index+of/" "rain.wav******"
Useful to see date and size that follow your target name...
bookmarklets: Bookmarklets: Weapons for the seeker
4)Googe's advance operators: "aeroplane finder" and other crap
Here is a
google's easy implementation:
from berlin to helsinki
Clicking on the first link)
you have an automatic price comparison.
On a similar path, there is the useful define: operator we have already seen, and all
the other advanced operators (stocks and other crap).
A possibly useful one is the 'change' operator: 234 USD in euro,
234 euro in CHF,
234 french money in GBP,
currency
of germany in malaysian money
and so on.
Another useful possibility are the mathematical operators:
twenty miles in kilometers
45 Fahrenheit in celsius
((894151*66771)+456)/1241: 48 109 070.8
But here you should not use google, for mathematical calculations
yahoo is better: ((894151*66771)+456)/1241=48,109,070.8114423826.
5) ElKilla bookmarklet (by ritz)
try it right away (no more clicking, press DEL to delete and ESC to cancel)
Right click and, in opera, select "add link to bookmarks"
More about bookmarklets in the javascript bookmark tricks essay.
http://fireddl.info/apps.htm: one of the many doors to the warez world
| SEARCHING FOR DISAPPEARED SITES | Top |
http://webdev.archive.org/
~ The 'Wayback' machine, explore the Net as it was!
Visit The 'Wayback' machine at Alexa,
or try your luck with the form below.
Alternatively, learn how to navigate through
[Google's cache]!
(http://www.netcraft.com/ ~ Explore 15,049,382 web sites)
VERY useful: you find a lot of sites based on their own name, which is another possible way to get to your target...
http://local.live.com/: pretty good ms concoction
http://maps.google.com/: google starter
http://maps.yahoo.com/: Yahoo (limited to the states and kanuk): for instance:
zip 56554
This is useful for ALL Europe:
http://www.nl.map24.com/ just input street, town and country :-)
The same in english: http://www.uk.map24.com/
Check also the ad hoc stalking section peoplesearch
Structure of the Web ~
WebStructure + Hidden Web ~
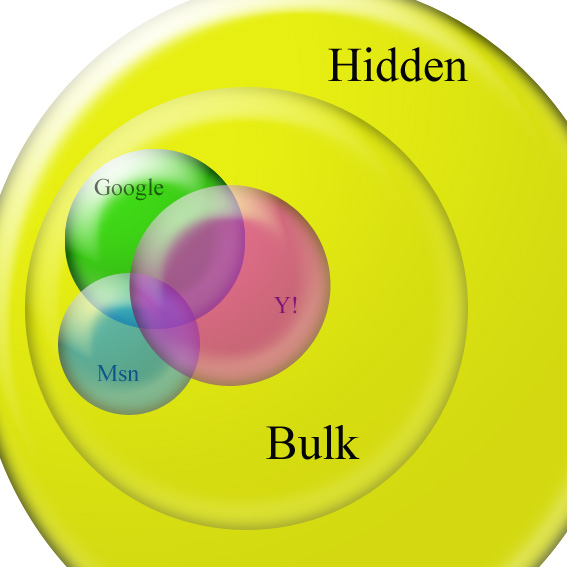
Main search engines' coverage ~
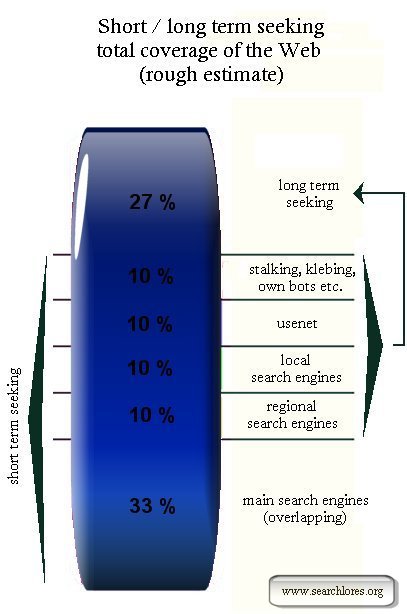
Short and long term seeking: % ~
Short and long term seeking: noise ~
Structure of the web

Short and long term seeking: percentages
| Main search engines' coverage | Top |
Bulk, Hidden web and main search engines' coverage
| The structure of the Web, Hidden web visible | Top |
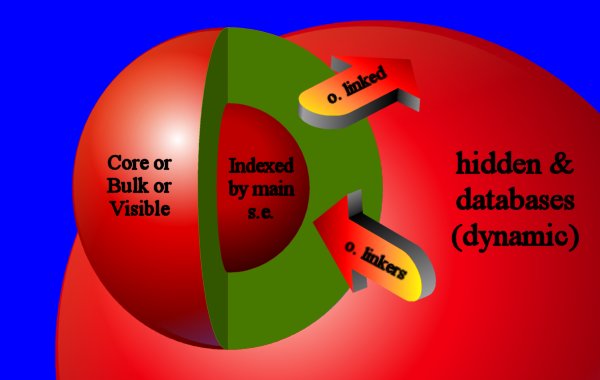
Structure of the web. Explain tie
model and diameter 19-21: do not dispair, never...
How big is the web? 24 billions? The s.e. cover between 1/3 and 1/4... 
| Short term searching/Long term searching: noise | Top |
Popularity versus time
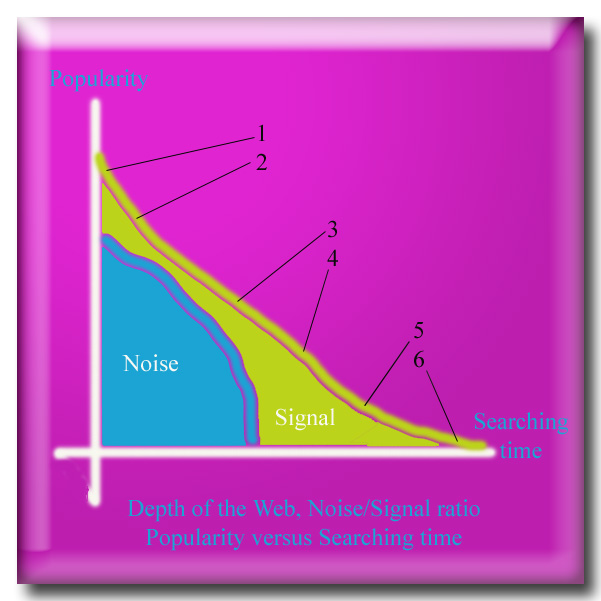
Both axes on a logarithmic scale
1) 5 minutes: Harry Potter,
the Goblet of Fire ~ the Half-Blood Prince (pdf or doc)
2) John Lennon "Imagine" (mp3 or ma4) (using imagine lennon mp3 OR ma4 OR ogg intitle:"Index of" -metallica and jumping direct to page 3)
3) Lord of the rings trilogy (pdf, html or audiobook)
4) Nero Wolfe: The girl who cried wolf, audio (or any other earlier radioshow)
5) an old Luis Vitton advertisement: (they want us to pay, so let's enlarge it manually
(http://media3.adforum.com/zrIf58670C/E/EU/EURR_01547/EURR_01547_0005730W.JPG... you want more?
http://media3.adforum.com/zrIf58670C/E/EU/EURR_01547/EURR_01547_0005730A.JPG
6) Several years: A Black and white Bulgarian film of the fifties, or even from the late seventies,
for instance
ADVANTAGE
Bulgaria 1978, 142 min. Dir.: Georgi Dyulgerov
What a search looks like
(Private investigations: The cranberry path) | Top |
"Your nose is as red as that cranberry sauce," answered Fan,
coming out of the big chair where she had been curled up for an
hour or two"
Hey, what the heck is a cranberry?
NON SPECIFIC LINKS/APPROACHES (can be used for most targets, doesn't need to be a cranberry :-)
google define: cranberry
wikipedia cranberry
yahoo education cranberry
cranberry: The Columbia Encyclopedia, 6th Edition.
Assorted links (out of thin air):
cranberry institute --> cranberryinstitute;
cranberry magazine --> cranberriesmagazine
cranberry bibliography --> Maine Uni bibliography
Wisconsin Cranberry School Proceedings (browse journals)
google images
& yahoo images
SPECIFIC LINKS/APPROACHES (cranberry-related: should be used only for plants-targets)
plants database
| Synecdochical searching | Top |
A
Synecdoche ("sin-EK-doh-kee") is the rhetorical or metaphorical
substitution of a part for the whole, or vice versa. This approach is widely used in searching,
because it allows you to get at your signal 'from the bottom', eliminating part
of the noise.
For some specific examples see synecdoc.htm.
Here let's just have "a visual look" at a search:
The red cylinder below represents the TOTALITY of accessible web sites that
could be of interest to you -in the context of your current search. The small
rings shows four different specific clusters of interesting sites.
Please remember that inside the cylinder the 'void' is only APPARENT!
That's the part
of the internet you cannot reach through the main search engines. There are interesting sites
there as well (as a matter of fact MANY more than on the 'accessible' outside), but to grab them you'll have to use
more advanced techniques than commercial engines :-)
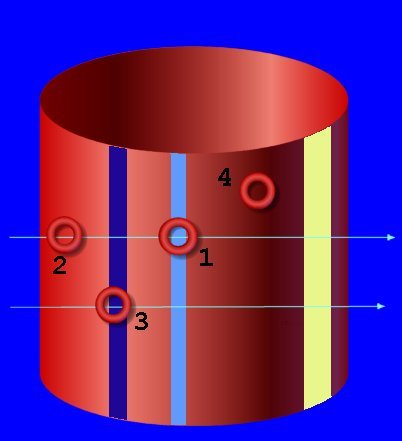
1 You land first time to an interesting cluster of sites trough your 'clean cut'
2 You have 'synecdochically' moved horizontally, modifying your original clean-cut
3 These sites will be relatively easy to find, they are both on an horizontal and on a
vertical synecdoche. Note that the signal width of the vertical synecdoches
(e.g. the yellow one on the right side of the image) may vary quite a lot,
while horizontal synecdoches' width seems more costant.
4 You'll never find this cluster
with your current synecdochical approaches, you'll have to
devise a COMPLETELY DIFFERENT cut.
Regional searching
The importance of languages and of online translation services and tools | Top |
One of the main reasons why the main search engines together cover (at best) just something less than 1/2 of the web
is a LINGUISTIC one. The main search engines are, in fact, "Englishcentric" if I may use this term, and
in many cases - which is even worse - are subject to a heavy "Americancentric bias".
The web is truly international, to an extent that even those who did
both physically travel and virtually browse a lot tend to underestimate.
Some of the pages you'll find may point to problems, ideals and aims so 'alien' from your point
of view that -even if you knew their languages or if they happen to be in English- you
cannot even hope to understand them.
On the other hand this multicultural
and truly international cooperation may bring some fresh air in a
world of cloned Euro-American zombies who drink the same coke with the same bottles, wear the same shirts,
the same shoes (and the same pants),
and sit ritually in the same McDonalds in order to perform their compulsory
and quick "reverse shitting".
But seekers need to understand this Babel if they want to add depth to their queries.
There are MANY linguistic aids out there on the web, and many systems that allow you to translate a page, or a snippet of text from
say, Spanish, into English or viceversa. But much rarer, and much more useful for us, are sites
that allow us to understand -eve roughly- pages written in Japanese, Chinese, Hindi, Russian, Korean, you name the funny alphabet :-)
As an example of how powerful such services can be in order to understand, for example, a Japanese site,
have a look at the following trick:
RIKAI
An incredible translator!
http://www.rikai.com/perl/Home.pl
Try it for instance onto http://www.shirofan.com/ See? It "massages" WWW pages and
places "popup translations" from the EDICT database behind the Japanese text!
for instance
http://www.rikai.com/perl/LangMediator.En.pl?mediate_uri=http%3A%2F%2Fwww.shirofan.com%2F
See?
You can use this tool to "guess" the meaning of many a Japanese page or -and especially- Japanese search engine options,
even if you do not know Japanese :-)
You can easily understand how, in this way, you can -with the proper tools- explore the wealth of results that the
Japanese, Chinese, Korean, you name them, search engines may (and probably will) give you.
Let's search for "spanish search engines"... see?
Let's now search for "buscadores hispanos"... see?
A 'portable' translator
| Top |
Highlight the following text:
Nous sommes en 50 avant Jésus-Christ. Toute la Gaule
est occupée par les Romains... Toute? Non! Un village peuplé d'irréductibles
Gaulois résiste encore et toujours à l'envahisseur. Et la vie n'est pas facile
pour les garnisons de légionnaires romains des camps retranchés de Babaorum,
Aquarium, Laudanum et Petitbonum...
click here: translate,
javascript:
params = '?langpair=fr|en';
if (document.getSelection) {
txt = document.getSelection();
}
else
if (document.selection) {
txt = document.selection.createRange().text;
}
if(txt)
params+="&text="+encodeURIComponent(txt);
void(window.open('http://translate.google.com/translate_t'+params, /keep on 1 line/
'translate','location=no,status=yes,menubar=no,scrollbars=yes, /keep on 1 line/
resizable=yes,width=547,height=442')) /keep on 1 line/
Ok, simple and quick (and rough) javascript. French into English was easy, of course. But -again-
note inside the code the params = '?langpair=fr|en'; snippet, that you can change to anything!
For instance to Korean
in order to translate or to browse starting from the following:
http://www.japanpr.com/shimane/shimane_default.htm
click here: Translate the page ko|en,
I would also like to draw your attention to the paramount
importance of names on the web... 
The ethical aspect...
An unfair society...
websearch importance nowadays recognized and obvious, you'll see tomorrow :-)...
libraries and documents: frills and substance...
the guardian of the light tower, the young kid in Central Africa and the yuppie in New York...
Ode to the seekers
Like a skilled native, the able seeker has become part of the web. He knows the smell of
his forest: the foul-smelling mud of the popups, the slime of
a rotting commercial javascript. He knows the sounds of the web: the gentle rustling of the jpgs,
the cries of the brightly colored
mp3s that chase one another among the trees, singing as they go;
the dark snuffling of the m4as, the mechanical, monotone clincking
of the huge, blind databases, the pathetic cry of the common user:
a plaintive cooing that slides from one useless page down to the next until
it dies away in a sad, little moan. In fact, to all
those who do not understand it,
today's Internet looks more and more
like a closed, hostile and terribly boring commercial world.
Yet if you
stop and
hear attentively, you may be able to hear the seekers, deep into the shadows,
singing
a lusty chorus of praise to this wonderful world of theirs -- a world that gives them everything they want.
The web is the habitat of the seeker, and in return for his knowledge and skill
it satisfies all his needs.
The seeker
does not even need any more to hoard on his hard
disks whatever he has found: all the various images,
musics, films, books and whatsnot that he fetches from the web...
he can just taste and leave there what he finds, without even copying it, because he knows that nothing
can disappear any more:
once anything lands on the web, it will always be
there, available for the eternity to all those that possess its secret name...
The web-quicksand moves all the time, yet nothing can sink.
In order to fetch all kinds of delicious fruits, the seeker just needs to raise his sharp searchstrings.
In perfect
armony with the sourronding internet forest, he can fetch again and again, at will, any target he fancies,
wherever it may have been "hidden". The seeker
moves unseen among sites and backbones,
using his anonymity skills, his powerful proxomitron shield and his mighty HOST file.
If need be, he can quickly hide among the zombies, mimicking their behaviour and thus disappearing into the mass.
Moving silently along the cornucopial forest of his web, picking his fruits and digging his juwels,
the seeker avoids easily the many vicious traps that have been set to catch
all the furry, sad little animals that happily use MSIE (and outlook), that use only
one-word google "searches",
and that
browse and chat around all the time without proxies, bouncing against trackers and web-bugs
and smearing all their personal data around.
Moreover the seeker is armed:
his sharp browser will quickly cut to pieces any slimy javascript
or rotting advertisement that the
commercial beasts may have put on his way. His bots' jaws will tear apart any database defense, his powerful
scripts will send
perfectly balanced searchstrings far into the forest.
So, that was it. Any questions?
Your own private investigations
The power of searching at your fingertips, what are you waiting for?
Start your own private investigations! Here two rather naïve examples.
1) Inflation
Don't you have the impression that the real inflation
we have all to endure (with more and more expensive everyday prices) is waaay more than that
ludicrous 2,1% (circa) that our powers that be claim year after year?
Well, there are a series of newspapers with their COMPLETE ARCHIVES on the web, searchable, for free.
Supermarket chains,
Aldi, Carrefour, you name it, have also published on the web their "fabolous" offers and prices.
Or try this:
http://www.google.com/catalogs :-)
You'll be able to find the older pages, as we have seen, using webarchive or similar web-snapshots repositories.
Assignement: Find the real inflation using all available data.
Some simple suggestions:
Use an
average of price components that is weighted and categorized in
approximately the same manner as the official Consumer Price Index.
Housing should represent the largest component at 40% with other categories having lesser impact.
The inflation rate should be calculated as a price multiplier with a base year of 1995,
to represent the number of "1st January 2006"
euro that are required to purchase what the equivalent of one "1st January 2006" EUR bought in 1995.
The annualized inflation rate is the
equivalent average compounded yearly inflation rate over the 10 year period.
Take account of education and medical care costs, also easy to find and check on the web (some combing
and social engineering will go
a long way in order to find them).
Create two subgroups: 1995-1999, 2000-2005
If you do it, you will soon realize that -while the euro itself has nothing to do with it-
the high inflation trend (around 6~8% real, not 2,1%) has been a (quite interesting) constant.
Purchasing power and living standards been steadily reduced, in Europe and elsewhere,
through a higher than admitted real inflation, which
translates of course into an automatic salary decrease for the great majority, bar speculators.
This has been coupled
with a prolonged (by law) "active life" (read shorter pension), and longer working hours (and working days) without
any salary compensation whatsoever for the unwashed masses.
2) Punishing greedy and corrupt ones
D'you have in your town a station being built, a new industrial area being planned, any building permits being granted,
any committee for the management of public housing?
You can bet that -in 99% of cases- someone is using law-loopholes and/or a net of political protection in order
to make money illegally.
But you now have the power of the seeker! Don't underestimate it.
You can explore all newspapers' databases, you can easily find
related
news, you can seek in many
languages...
In a more and more Internet-oriented society a seeker can find out quite a lot about
his targets.
You can stalk people, lure and/or troll info out of them or about them, find out where they live,
how much they earn, when, where and
how they started to work (political appointment? Public competition? Father's connections?)
You can, with simple social engineering tricks, get in touch with their co-workers, enter their databases,
have a look at the code of their doc format documents, where word, often enough and per default, keeps all the
corrections and changes which have been made to a document...
Your 'private investigations' may be small crumbs, but even small crumbs may grind the
well-greased wheels of your own local political/commercial vermine!

|
 |
 |
 |
 |
| The Door | the Hall | The Library | The Studio | The Garden path |

